Cookies, those little bits of code that identify us as we browse online, are used to identify return user sessions, offer better content, or simply monitor user activity online. Brands rely on them to improve their marketing and customer experience in a myriad of ways.
However, in recent years, users have begun to rebel against what feels like to many an invasion of privacy. While most of us appreciate it when a browser remembers our passwords or keeps items in a shopping cart even after we leave a page, there's another side to cookies.
The Trouble with Cookies
Those ads that follow you around the internet for weeks after you visit a website or that seem just a little too personal? They're served up because of information stored in those cookies, which could include your age, gender, location, and interests. This can feel intrusive, and it raises real concerns about the way ad networks handle personal information. In fact, malicious cookies can be used to create a detailed profile of any of us which is then sold to the highest bidder without our consent!
Not everyone is excited to see ads based on their browsing history. Facebook clearly keeps an eye on what I've been looking at lately. For example, I just had to purchase a new refrigerator, which means I was looking at appliances. And I did just restock my skincare supplies...
 It's not surprising then that some countries are imposing serious restrictions on the use of third-party browser cookies. Meanwhile, enterprising app creators and web browsers offer more and more options allowing users to block and delete this information.
It's not surprising then that some countries are imposing serious restrictions on the use of third-party browser cookies. Meanwhile, enterprising app creators and web browsers offer more and more options allowing users to block and delete this information.
For example, Google announced that they will no longer sell ads targeted by an individual users’ browsing habits, and its Chrome browser will no longer allow cookies that collect that data, though there will be tracking of anonymized cohorts. In other words, you're no longer individually identifiable, but are part of a group of anonymous users with similar characteristics.
But while we are all for protecting privacy, many marketers dread the day when 3rd-party cookies are no more. Especially because they enable retargeting ad campaigns which are a staple in online advertising for good reason. Showing a specific ad to someone based on pages they've visited or action they've taken on your website are infinitely more effective than advertising to a cold audience.
If you're a pro, skip down a bit to find five ways marketers can thrive in a world without cookies. Otherwise, let's start with the basics.
How Do Cookies Work?
When you load a webpage, the browser sends a request to the server to deliver the requested page content (home page, blog post, product page, etc.).
A cookie is a small piece of code that the server and browser share. Every time a user visits a page, all of the cookies associated with that user go with them. This makes it easy to keep track of a user's behavior including browsing history, purchases, and preferences.
In fact, cookies tell us whether each page visit is made by one very interested visitor, or one hundred people visiting one page each.
Third-party cookies, the ones specifically driving the privacy push, are used by ad companies to track your browsing activity, building a profile about you and your perceived interests so they can send targeted ads to you.
How Do Marketers Use Cookies?
There are two main ways legitimate businesses employ cookies.
- Personalization - who doesn't appreciate not having to re enter your shipping information every time you place a repeat order on a website? While convenient for users, it's also a great way to keep people on the site longer and to keep them coming back.
Personalization can also be used to serve up more relevant information and products when a user revisits a site or even to address them by name.
- Tracking - generally used for advertising, tracking cookies help businesses and advertising platforms see what users are interested in so they can serve up targeted ads. Want to show a particular add only to people who visited a certain page? That's possible with cookies.
 HubSpot recognizes me when I want to download something - because of cookies! This is convenient for me, and increases submission rates for them.
HubSpot recognizes me when I want to download something - because of cookies! This is convenient for me, and increases submission rates for them.
What does Cookieless mean for marketing and advertising?
The size of the audiences generated by third-party data (for example, those you use for Facebook ad targeting) will shrink considerably as users have more control over their data. Advertising using data Google collects on its own properties (search, YouTube) will become more expensive as other options shrink.
Ads like this, that use Google's own first-party data, will becoming increasingly costly.

But this pending revolution is already moving always-adaptable marketers to new, even better solutions.
How will advertising work without cookies?
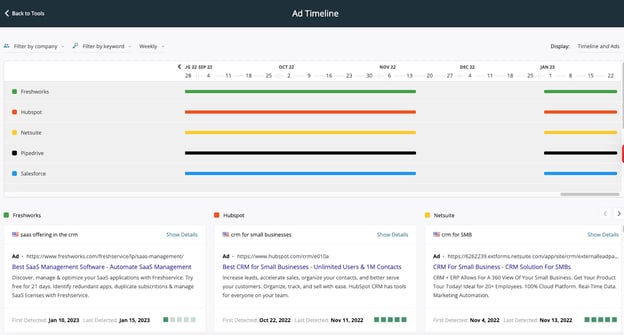
You can still retarget users if you have your own data. Your email list, for example, is a perfect source for your retargeting campaign. One benefit of using your own data is that your competitors will never be able to target the same list! Curious about how you can track your competitors' advertising?
There are new, even smarter ways to target ads including contextual targeting, which enables advertisers to reaction to insights gathered in the moment as the user is visiting a site. This on-the-fly data can target and scale campaigns at least as well as cookies do.
Your competitor ad strategy is an open book to you with Kompyte.
5 Ways to Thrive in a Cookieless World
With cookies facing increased scrutiny to the point that many of the most useful to marketers will no longer be available, is there a way to achieve the same results in a post-cookie world?
1. Brush up on Your Ad Testing Skills
Most ad platforms make it pretty easy to see which ads are working well and which are not. However, because in many cases you will be targeting a broader audience, you'll want to keep a closer eye on these indicators, checking more frequently that you did previously.
You may also want to try AI-based bidding on platforms such as Google and Pinterest. Your bids are optimized in real time for best results - and you don't have to do a thing. Google's Smart Bidding even optimizes for conversions.
2. Invest in First-Party Data
If Google isn't going to tell you about your visitors, you'll have to ask them yourself! Growing your email list, launching on-line surveys, and building out your SMS list are all ways to ensure you keep in touch with your most important visitors.
3. Conduct More Market Research
Understanding the collective pain points and desires of your website visitors will allow you to offer content that suits their needs - without cookies!
Some of the ways to get to know your customer in this way include:
- Examining the data you do have (Google analytics, ad reports, etc.) to see what is resonating and what isn't.
- Talk to them. Focus groups and 1:1 interviews are priceless here. If your sales team is recording sales calls with a service like Gong, you can review calls to see which themes pop up consistently.
- Join communities of people with similar characteristics of your best customers. Offer value or simply lurk, but don't go there to sell.
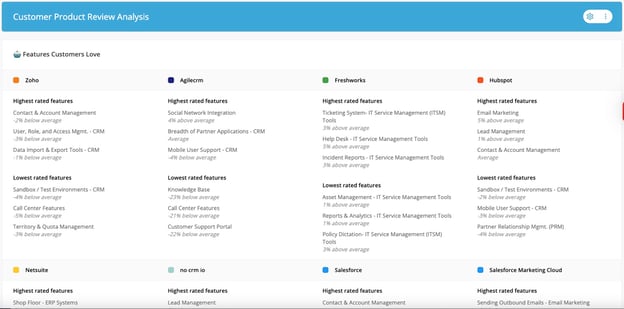
- Read every customer review and your competitor reviews. Pro tip: Kompyte makes this easy by flagging all new product reviews for you and your competitors.
4. Create More Partnerships in Marketing
There's a reason people pay to sponsor industry newsletters and events. If you know where your customers and potential customers get their information, use those audiences! Whether you pay to sponsor a podcast, newsletter, online event or you work together to create a webinar or course, you don't have to do this on your own.
Working with industry experts is another way to reach a targeted audience without relying on cookies. Find the people your customers look up to and make a deal! According to Influencer Marketing Hub, "More than 75% of brand marketers intend to dedicate a budget to influencer marketing in 2022," so you won't be alone.
5. Use Contextual Targeting
In contextual advertising, ads are placed on specific web pages based on the page content. For example, when reading an article on the cost benefits of modular housing on Time magazine, you'll see ads for financial services, credit reporting, and retirement advice. Someone researching home buying options likely has financial health on their mind. 
Then there's this example from Search Engine Land. If you're interested in an article about creating long-form content, you might be interested in marketing automation. No cookies required for that targeting!

Your competitors may already have gone all in on one or more of these cookieless options, and monitoring their activity can be a great way to inspire your own marketing (and to stay one step ahead of them).
You can spend time manually tracking their website, social, and advertising activity getting started with a handy template like this, or you can get it all done in an hour a week with Kompyte.

